第二章 机器学习简介
机器学习,也是人工智能中发展最快的领域。 相信通过本章中机器学习和深度学习概念的介绍,你会对它更有体会。
2.1 机器学习简介
2.1 机器学习简介
> 人工智能、机器学习与深度学习
首先我们先来看一下下面这张图。
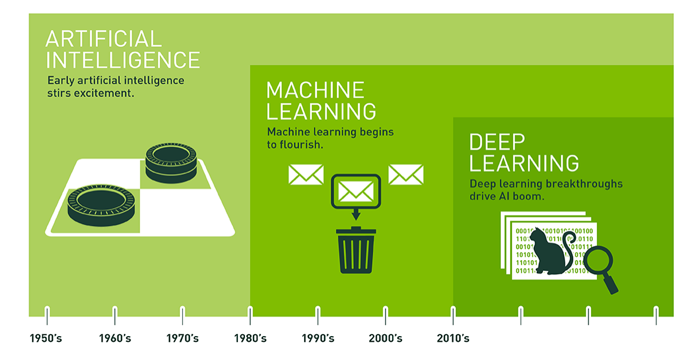
人工智能(Artificial Intelligence)就是用机器模拟人的意识和思维。
机器学习(Machine Learning)则是实现人工智能的一种方法,是人工智能的子集。
深度学习(Deep Learning)就是深层次神经网络,是机器学习的一种实现方法,是机器学习的子集。
在20世纪50年代中期,人工智能开始兴起。到了20世纪80年代,机器学习开始繁荣起来,在这张图中的垃圾邮件分类就属于机器学习。到2010年左右,深度学习得到了极大的发展,把人工智能推向了新的高潮,最常见的深度学习有图片分类等等。
> 机器学习
机器学习是人工智能的一个分支,它是实现人工智能的一个核心技术,即以机器学习为手段解决人工智能中的问题。
机器学习是通过一些让计算机可以自动“学习”的算法并从数据中分析获得规律,然后利用规律对新样本进行预测。
机器学习如果用形式化的语言进行描述,就是对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么就称这个计算机程序在从经验E学习。
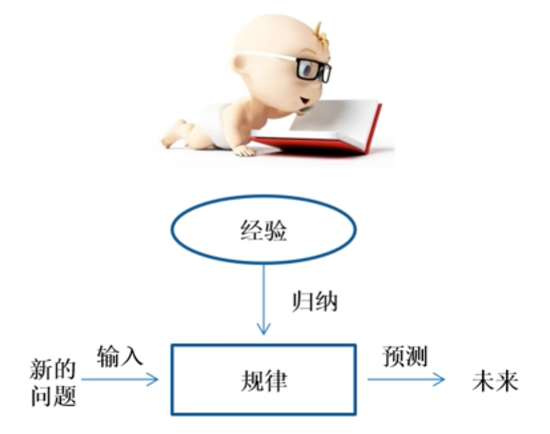
人类在学习中是什么样的呢?我们可以举一个简单的例子:一个小宝宝,他的妈妈买回来一个苹果并告诉他这是苹果,那么他就会对苹果有所认知,第二天,他的妈妈买了一个不同样子的苹果,但是告诉他这个还是苹果,那么他就会对苹果有新的认知,经过认识不同种类的苹果,小宝宝对苹果形成了自己的认知,可以去判断什么样的东西是苹果。他能根据自己的经验总结出一个规律,然后对于新看到的物品可以去判断它是否是苹果,其他的水果也是同理。这样就完成了一个人类学习的过程。
对于机器学习来说,它需要大量的历史数据,而且同时需要告诉它正确的分类结果,比如什么是香蕉,什么是苹果。经过这样的训练,它会形成一个模型,当有新的数据进来,它会根据模型算出这个物品到底属于什么样的类别。
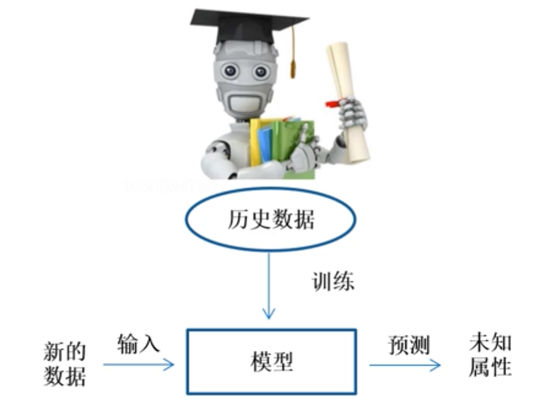

其实人类学习的过程和机器学习的过程很类似,人类就是通过各种各样的经验归纳出规律,当有新问题产生时,通过头脑运作产生相应的结果。而机器是通过历史数据做训练,形成一个训练好的模型,当有新的数据输进来,通过这个训练好的模型做计算,得到的结果就是预测出来的新的未知属性。
> 机器学习典型求解问题类型
机器学习可以分为有监督学习、无监督学习、半监督学习、强化学习。

> 有监督学习
有监督学习(Supervised Learning)指的是事先需要准备好输入与正确输出(区分方法)相配套的训练数据,让计算机进行学习,以便当它被输入某个数据时能够得到正确的输出(区分方法)。
有监督学习需要有大量的训练数据,不仅仅是输入,还需要区分方法,也就是需要正确的数据标签。
> 无监督学习
无监督学习(Unsupervised Learning)的目的是让计算机自己去学习怎样做一些事情,所有数据只有特征而没有标记。
无监督学习被运用于仅仅提供输入用数据、需要计算机自己找出数据内在结构的场合。其目的是让计算机从数据中抽取其中所包含的模式及规则。
> 半监督学习
介于有监督学习和无监督学习之间的是半监督学习(Semi-supervised Learning)
半监督学习的训练数据一部分有标记,另一部分没有标记,而没有标记数据的数量常常远大于有标记数据的数量。
半监督学习的基本规律是:数据的分布必然不是完全随机的,通过结合有标记数据的局部特征以及大量没有标记数据的整体分布,可以得到比较好的分类结果。
> 强化学习
强化学习(Reinforcement Learning)是解决计算机从感知到决策控制的问题,从而实现通用人工智能。
强化学习是以目标为导向的。它的训练是从一张白纸的状态开始,经由许多个步骤来实现某一维度上的目标最大化。简单的来说,就是在训练过程中,不断地去尝试,错误就惩罚,正确就奖励,由此训练得到的模型在各个状态环境中都最好。
对于强化学习来说,它虽然没有标记,但有一个延迟奖励与训练相关,通过学习过程中的激励函数获得某种从状态到行动的映射。
强化学习强调如何基于环境而行动,以取得最大化的预期利益。
强化学习一般适用于游戏、下棋等需要连续决策的领域。
> 无监督机器学习的典型应用模式
前面提到过,无监督机器学习是不需要标记的,比如屏幕中有一大堆点,我们需要进行聚类,即所谓的“物以类聚,人以群分”,使得这些点被分成了下图中的三组。它常见的算法是K-Means算法。

在无监督学习中还有一个典型的场景是关联规则抽取。最常见的是超市物品的摆放。超市中的物品摆放通常是有一定讲究的,他们通过分析超市里的销售数据发现,啤酒和纸尿裤同时被购买的概率比较大,超市就根据这个情况调整了货物的摆放,在啤酒边上放上了纸尿裤,在原本卖纸尿裤的货架附近放上了啤酒,这样一来确实促进了购买力。
> 有监督机器学习的典型应用模式
预测问题主要针对的是连续的数据。
下图是Google机器学习速成课程中的一个例子,它反映了每分钟虫鸣和温度之间的关系,而这个规律可以用一条直线来表示。那么机器学习所做的事情,就是去确定这条直线的截距和斜率。针对这些连续数据,我们可以根据所建立好的模型,用每分钟虫鸣数来预测所对应的温度。它常见的算法是线性回归、Gradient Boosting、AdaBoost、神经网络算法。

分类问题主要针对的是离散的数据。
下图我们可以看成一个工厂所加工的螺丝,它有重量和长度,而最终大量的坐标数据(螺丝)被分为两类,一类是红色的,代表合格品;还有一类是蓝色的,代表残次品。它们被一条虚线明显的分隔开来。如果给出一颗新的螺丝,我们可以根据它所落在的位置来判断它是否合格,因此实现了一个二分类的应用。它常见的算法是逻辑回归、决策树、KNN、随机森林、支持向量机、朴素贝叶斯、神经网络算法。

2.2 深度学习
> 神经元
1904年,生物学家了解了神经元的组成结构。
神经元通常是由细胞核、树突、轴突、突触等组成。一个神经元有多个树突用来接收信息,一个轴突用来传送信息。

1943年,心理学家Warren McCulloch和数学家Walter Pits发明了神经元模型。可以看到下图的左边有许多的输入,类似于神经元的树突,经过一个细胞核的处理,也就是下图中加权求和的部分,再通过激活函数,最后得到一个输出。

两者的结构非常相似,这个神经元模型的结构也非常简单,但是仅仅只有一个这样的结构,也许做的事情并不是特别有用,当亿万个这样的简单结构组合在一起,就可以完成更加复杂的事情。现在深度神经网络在各个领域大放异彩,其实它最基本的结构仍然是这样的简单结构。
> 神经网络
如果我们把多个单一的神经元组合在一起,就会有一些神经元的输出作为另一些神经元的输入,这样就构成了神经网络。把这些神经元看成一个整体的话,这个结构就具有了输入和输出,我们把接收数据输入的层叫做输入层,而最后输出结果的层叫做输出层,中间的神经元组成的中间层叫做隐含层或者隐藏层。
神经网络层数的判别主要是由隐藏层的数量决定的。下图是一个单层的神经网络,这个神经网络在输入层有4个神经元,隐藏层有5个神经元,输出层有2个神经元。

我们需要根据具体要解决的问题来设计相应的神经网络。通常来说,输入层和输出层的神经元数量是固定的,而中间隐藏层到底需要几层,每一层需要多少个神经元的个数是可以自由调整的。
举一个手写字符识别的例子,它的输入是一张手写数字的图片,大小是28×28,即总共有784个像素点,把这些像素点作为输入,那么输入层总共需要784个神经元,而最终得到的结果是一个十分类问题,即可能的结果在0-9之间,所以输出层的神经元个数为10个,这就是设计手写字符识别的神经网络时所需要注意的问题。它的输入层是由图片的特性所决定的。
接下来,我们来看看神经网络具体是怎样工作的。
可以看到下图中输入层的三个节点分别为x1、x2、x3,隐藏层有三个节点,输出层有两个节点。这是一个全连接网络,也就是说,后一层的某一个节点和前一层的每一个节点都相连。

我们以隐藏层中第一个节点为例,它跟x1、x2、x3都相连,但x1、x2、x3对它的作用并不一定相同,x1、x2、x3都带了相应的权值,这个权值由前面这个节点跟它之间的边确定,因此我们可以得到下图的式子:

上述式子中的w就是权值,而b是偏置项,加上偏置项使得整个神经网络的表现力变得更强。
通过这样的公式去做计算,整个神经网络的表现其实还是不足的,这个不足主要体现在后一层跟前一层的关系仍然是一个线性关系,而人们在研究生物体的细胞时候发现,当神经元受到刺激,它的兴奋程度需要超过某一限度,神经元才会激发出反应,从而输出神经脉冲,也就是说它的轴突才会对下面一层进行输出,而当它的兴奋程度低于某一限度时,神经元就不会被激活,它就当作没有接受到信息,也就不会产生反应脉冲。
在自然界中,生物神经元的输入和输出,并不是按线性的比例关系直接计算得到的,因此,我们在设计人工神经网络的时候也参照了这一点,设计了一个“激活函数”。对前面所得到的结果部分做一个非线性化的计算处理,这样使得整个神经网络的表现力变得更好。
在图2-11中我们可以看到,中间隐藏层的部分实际上被分成了两块,前部分是z,后部分是a,图2-12中公式里的a就相当于图2-11中隐藏层的z,它是一个线性的计算和,然后通过一个非线性的激活函数,来计算它下一步的值,也就是变成了下图所示的公式。因此,真正a的值是在原来计算的基础上用一个非线性的激活函数,做了一次非线性的处理,这样能够得到更好的结果。

> 常见的激活函数
在这里我们简单介绍两种简单的激活函数。
> Sigmoid激活函数
S型(Sigmoid)激活函数可以把它的输入转变成介于0-1之间的值。
它的公式如下图所示:

通过下面这张图,我们可以看到,当x=0时,它的值为0.5;当x趋于无穷大,它的值无限接近于1;当x趋于无穷小,它的值无限接近于0。

> ReLU激活函数
修正线性单元激活函数(ReLU),它的效果通常来讲比Sigmoid好一些,而且非常容易计算。
它的公式如下图所示:

通过下面这张图,我们可以看到,当x>0时,它的值为其本身;当x<=0时,它的值等于0。

> 深度神经网络
神经网络算法的核心就是计算、连接、评估、纠错和训练,而深度学习的深度就在于通过不断增加中间隐藏层数和神经元数量,让神经网络变得又宽又深,让系统运行大量数据,训练它。
“深度”一词没有具体的特指,一般就是要求隐藏层很多(一般指5层、10层、几百层甚至几千层)。

> 卷积神经网络
卷积神经网络(Convolutional Neural Networks, CNN)是深度学习中最重要的概念之一。
20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现,其独特的网络结构可以有效降低神经网络的复杂性。
1998年,Yann LeCun提出了LeNet神经网络,标志着第一个采用卷积思想的神经网络面世。但是这个神经网络在当时并没有火起来,主要还是因为对计算量的要求比较大,而当时的计算能力有限,也没有使用GPU,所以它的效果反而没有其他机器学习的效果好,比如支持向量机(Support Vector Machine, SVM)。
LeNet的结构如下图所示,里面分了一些卷积层和池化层,这些概念我们在之后的课程中会详细讲解。

卷积神经网络最大的特点就是卷积和池化。这个图例的输入是32×32,图中的C1、C3、C5都是卷积层,卷积核会在这个二维的图形平面上移动,跟卷积核做计算,不断提取出新的图像,这些新的图像可以获取一定的特征。这里还有两个池化层S2和S4,池化的过程一方面可以降低模型的过拟合程度,另一方面可以强化图像中的显著特性。在最后,它也用了两个连接层进行连接,所以整个网络结构还是比较复杂的。
> AlexNet
2012年,卷积神经网络在图像识别领域出现了一个惊人的表现,也就是在ImageNet的大规模视觉识别挑战赛上,AlexNet获得了冠军,由此引发了新一轮对神经网络的热情。
AlexNet可以认为是最早的现代神经网络,它证明了卷积神经网络在复杂模型下的有效性,而且它当时使用了GPU去训练,使得在可接受的时间范围内,得到比较好的结果,推动了有监督深度学习的发展。
下面是AlexNet的网络结构图。它本质上就是把LeNet的深度进行了扩展并运用了一些ReLU激活函数以及dropout这个防止过拟合的技术。

AlexNet有5个卷积层和3个最大池化层,而且它可分为上下两个完全相同的分支,这两个分支在第三个卷积层和全连接层上可以相互交换信息。
AlexNet在2012年引起了轰动,主要是因为在ImageNet的大规模视觉识别挑战赛中获得了冠军,它的成绩领先第二名非常多而且比2011年提高了10个百分点,是非常不容易的。随着深度学习网络的发展,到了2015年的时候,对这些图片的识别已经超过了人眼的精确度。

ImageNet本身的数据集是非常大的,有1400多万幅图片,涵盖了2万多个类别,所以在这个比赛中获得冠军而且识别度这么高是非常有分量的。
> VGG Net
VGG Net有5个卷积层组,有2层全连接层用于提取图像特征,还有1层全连接层用于分类特征,根据5个卷积层组每一个组的不同配置,卷积层数是从8到16递增的,它的网络结构图如下图所示:

VGG Net的泛化性很好,常用于图像特征的抽取、目标检测、候选框生成等等。它最大的问题在于它的参数数量非常多,一般来说,根据它的层数有两种典型的,一种是VGG 16,还有一种是VGG 19。VGG 19基本来说是参数量最多的卷积神经网络架构。
> Google Net
Google Net使用了一种Inception的网中网结构,即原来的节点现在也是一个网络,这样既保持了网络结构的稀疏性,又不降低模型的计算性能。可以说Inception网络是CNN分类器发展史上一个重要里程碑。在Inception出现之前,大部分流行的CNN仅仅是把卷积层堆叠的越来越多,使网络越来越深,以此希望得到更好的性能,而Google Net使用了Inception结构之后,整个网络结构的宽度和深度都可以扩大,能够带来较大的性能提升。

> 神经网络大观
神经网络的发展经过了这么多年,其实已经形成了很多种不同的结构。
下面这张图中列出了一些典型的结构,有兴趣的同学可以了解一下。

> 深度学习的发展历程

1943年,提出了数学上的神经元模型,开启了神经网络发展的起点。
1958年,提出了感知机模型,这个感知机模型也是首个可以学习的人工神经网络。引发了神经网络研究的第一次兴起。其实它只是一个单层的神经网络,比较单薄。
1969年,这个领域的权威学者Minsky 用数学公式证明了只有单层神经网络的感知机无法对异或逻辑进行分类,Minsky还指出要想解决异或可分问题,需要把单层神经网络扩展到两层或者以上。然而在那个年代计算机的运算能力,是无法支撑这种运算量的。只有一层计算单元的感知机,暴露出了它的天然缺陷,使得神经网络研究进入了第一个寒冬。
1986年,Hinton等人提出了反向传播方法,有效解决了两层神经网络的算力问题。引发了神经网络研究的第二次兴起。
1995年,支持向量机诞生。支持向量机可以免去神经网络需要调节参数的不足,还避免了神经网络中局部最优的问题。一举击败神经网络,成为当时人工智能领域的主流算法,使得神经网络进入了它的第二个冬季。
1998年,诞生了卷积神经网络,也就是LeNet,这是第一个卷积神经网络,也为之后深度学习打下了基础。
2006年,深层次神经网络出现。深度学习的概念由Hinton等人于2006年提出。基于深度置信网络(Deep Belief Network,DBN)提出非监督贪心逐层训练算法,为解决深层结构相关的优化难题带来希望,随后提出多层自动编码器深层结构。也正是因为DBN克服了深度神经网络训练时的缺点,才使得神经网络重新焕发了生机,而且一发不可收拾。此外Lecun等人提出的(Convolutional Neural Network,CNN)是第一个真正多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能。最早被用来识别支票上的手写数字,所用的网络是LeNet。
2012年,卷积神经网络在图像识别领域中的惊人表现,又引发了神经网络研究的再一次兴起。
2016年,AlphaGo战胜了围棋世界冠军,又引爆了新一轮的深度学习高潮。
回顾深度学习整个的发展历程,其实有点像人工智能的发展历程,也经历了几起几落。此外,深度学习仍在发展之中,它还存在着一些问题,比如面向任务单一、依赖于大规模有标签数据、几乎是个黑箱模型,可解释性不强等等。不过无监督的深度学习、迁移学习、深度强化学习和贝叶斯深度学习等这些新的算法越来越受到关注。另外,我们可以感觉到现在所说的人工智能基本都是用深度学习来做代表的,深度学习具有很好的可推广性和应用性,但不是人工智能的全部,未来人工智能需要有更多类似技术。
2.3 深度学习框架
通过下图我们可以看到,主流的深度学习框架种类还是非常多的。

下面我们来了解一下这张排行榜。这张排行榜的作者是Keras的作者、谷歌研究科学家François Chollet,他在三月份时晒出了一张图,他基于Google Search Index,展示了过去三个月,ArXiv上提到的深度学习框架排行。

从这张排行榜中我们可以看到,TensorFlow是最受欢迎的,其次是Keras,之后是Caffe、PyTorch等等。我们选择其中几个来了解一下。
> Theano
Theano的开发始于2007年,由加拿大的蒙特利尔大学开发。由于出身学界,它最初是为学术研究而设计的,在过去的很长一段时间内,Theano是深度学习开发与研究的行业标准。
Theano是一个比较低层的库,适合数值计算优化。支持自动的函数梯度计算,带有Python接口并集成了Numpy,可以说Theano是Python的一个数值计算库。但它也有些缺陷,它不支持多GPU和水平扩展。
随着TensorFlow在谷歌的支持下强势崛起,Theano日渐式微,这过程中的标志性事件是:创始者之一的Ian Goodfellow放弃Theano转去谷歌开发TensorFlow。
> Caffe
Caffe在2013年就已问世,是老牌的框架之一,它的创始人是加州大学伯克利分校的中国籍博士生贾扬清先生。
Caffe的全称是“Convolutional Architecture For Feature Extraction”,意为“用于特征提取的卷积架构”,它的设计初衷是为了计算机视觉。但它也存在灵活性不足的问题,为模型做调整常常需要用到C++和CUDA。
在2017年4月Facebook发布了Caffe2,Caffe2可以看作是Caffe更细粒度的重构,在实用的基础上,增加了扩展性和灵活性。
> PyTorch
在讲PyTorch之前,我们先来了解一下Torch。
Torch是一个非主流的深度学习框架,它的开发语言是基于20世纪90年代诞生于巴西的Lua,而现在主流的机器学习界所采用的语言,基本上都是Python,因此,用Lua显得有些“非主流”。
Facebook的人工智能研究所使用的框架就是Torch。Torch非常适用于卷积神经网络,它的灵活度更高,因为它是命令式的,所以支持动态图模型。
大多数的深度学习框架都是支持静态图模型的,也就是说,它要先把模型定义好,然后再进行运行计算,而Torch的灵活度更高,它可以像交互式的命令一样,边运行边更改,在运行的过程中去定义它的图模型,这样叫做动态图模型。
2017年初,Facebook在Torch的基础上,针对Python语言发布了一个全新的机器学习工具包PyTorch。PyTorch可以说是Torch的Python版,增加了很多新的特性。
2018年4月,Facebook宣布Caffe2将正式将代码并入PyTorch。
> MXNet
MXNet是亚马逊AWS选择支持的深度学习框架。
MXNet尝试将两种模式无缝的结合起来:在命令式编程上,MXNet提供张量运算,而声明式编程中MXNet支持符号表达式。这样,用户可以自由地混合它们来快速实现自己的想法,也就是说,它结合了静态定义计算图和动态定义计算图的优势。
MXNet支持C++、Python、R、Julia、Go语言,但是它的学习难度较高。
> CNTK
Microsoft 认知工具包(Cognitive Toolkit) 之前被大家所知的缩略是CNTK。
2016年,微软宣布已经在GitHub上向外部开发人员开源其人工智能工具包CNTK(Computational Network Toolkit)。
CNTK工具包中的语音和图像识别速度比较快,而且它还具有着更为强大的可扩展性——开发者可以用多台计算机实现GPU的扩展,从而能够更加灵活地应对大规模的实验。对于广大Windows系列的开发者来说,它支持C#是一个非常好的福音。
> Keras
Keras是一个非常高层的库,可以工作在Theano、TensorFlow和CNTK之上。
Keras强调极简主义——你只需要几行代码就能构建一个神经网络。它是为支持快速实验而生,能够把你的idea迅速转换为结果。它的句法相当明晰,文档也非常好,同时也支持Python。
> DL4J
DL4J(Deep Learning For Java)是基于JVM、聚焦行业应用且提供商业支持的分布式深度学习框架,其宗旨是在合理的时间内解决各类涉及大量数据的问题。
它对Java的支持就是它最大的特点。它可以与Hadoop和Spark集成,可使用任意数量的GPU或CPU运行。这就为广大的Java从业人员提供了一个好的深度学习工具。
> Chainer
Chainer是一个专门为高效研究和开发深度学习算法而设计的开源框架。它也是基于Python的独立的深度学习框架。
Chainer在训练时,“实时”构建计算图,“边运行边定义”的方法使构建深度学习网络变得灵活简单,也就是说,它支持动态图定义。
这种方法可以让用户在每次迭代时或者说对每个样本都可以根据条件更改计算图,同时也很容易使用标准调试器和分析器来调试和重构基于Chainer的代码。
> Paddle Paddle
Paddle Paddle是百度旗下深度学习开源平台。
Paddle(Parallel Distributed Deep Learning,并行分布式深度学习)。
2016年9月1日百度世界大会上,百度首席科学家Andrew Ng(吴恩达)首次宣布将百度深度学习平台对外开放,命名PaddlePaddle。有趣的是,Andrew Ng认为Paddle Paddle比Paddle更容易被大家所记住,后来事实证明也的确如此。
2016年9月27日,Paddle Paddle在开源社区GitHub以及百度大脑平台开放。
百度资深科学家、Paddle Paddle研发负责人徐伟介绍:“在PaddlePaddle的帮助下,深度学习模型的设计如同编写伪代码一样容易,设计师只需关注模型的高层结构,而无需担心任何琐碎的底层问题。未来,程序员可以快速应用深度学习模型来解决医疗、金融等实际问题,让人工智能发挥出最大作用。”
> TensorFlow
“A machine learning platform for everyone to solve real problems”,即对每个人来解决现实问题的机器平台,这也是TensorFlow存在的宗旨。
它不仅在上层支持神经网络,它还很全面的支持其他机器学习的算法,比如K-Means、决策树、支持向量机等等。它对语言的支持也很多,比如Python、C++、Java等等。此外,在硬件层面,它也可以支持CPU、GPU、TPU、Mobile(移动平台上)等等。

TensorFlow还提供了一个叫做TensorBoard的可视化工具(图2-29),这个工具非常强大,它可以基于运行的一些日志文件,可视化的把模型训练和结果展现出来。包括计算图可视化(图2-30),里面一些精确度、损失率都可以很好的可视化出来,方便用户对模型的调优。


此外,TensorFlow提供了不同层次的接口,从低层到高层。越低层越灵活、越容易去控制,而越高层越容易使用。最低层的就是TensorFlow直接提供的低层接口。
我们这门课大多数都是基于这一层的接口来讲解应用开发的,因为它能够比较好的去反映TensorFlow的一些设计理念以及深度学习的一些原理。虽然它很底层,但是它的调用并不是很困难,还是很容易去理解的。
当然,为了初学者更好地去使用,它还提供了Keras这个高层的接口。在它上面的是Estimator,Estimator支持分布式地执行。再上面就是一些预设好的模型库,这些模型库可以由用户直接拿来使用(开箱即用)。

TensorFlow支持多种开发语言,除了前面提到过的一部分,下图中也列举了其他的发开语言,不同的软件发开人员都可以找到TensorFlow的支持。

TensorFlow.js我们在后面中也会有例子来讲解,它可以直接利用JavaScript在网页上进行机器学习的训练和使用。
TensorFlowLite使得在PC上或者在服务器上训练好的TensorFlow的模型,可以通过转换,变成TensorFlowLite的格式,去支持移动端的应用,比如安卓、ios、树莓派之类的,使得移动的人工智能变为现实。

2.4 本讲小结与作业
> 本讲小结
本章我们主要介绍了有关深度学习的知识,经过对深度学习一系列的了解,大家是不是对基于TensorFlow的深度学习应用开发充满期待呢?在下一章中,我们将会讲解有关TensorFlow的基本概念。